The LLM inference gateway: what sits between authenticated callers and the model, and what belongs somewhere else
The LLM inference gateway is the identity-aware policy enforcement point between authenticated users or agents and any model endpoint. It is the layer where authorization, data classification, and audit-record production live. This piece defines the term, walks through the four fields the gateway resolves per request, contrasts it with the inference server, model router, and API gateway it is often confused with, and shows why the audit-write path must be isolated from the caller. Applies to any deployment running an OpenAI-compatible or provider-native LLM API in production.
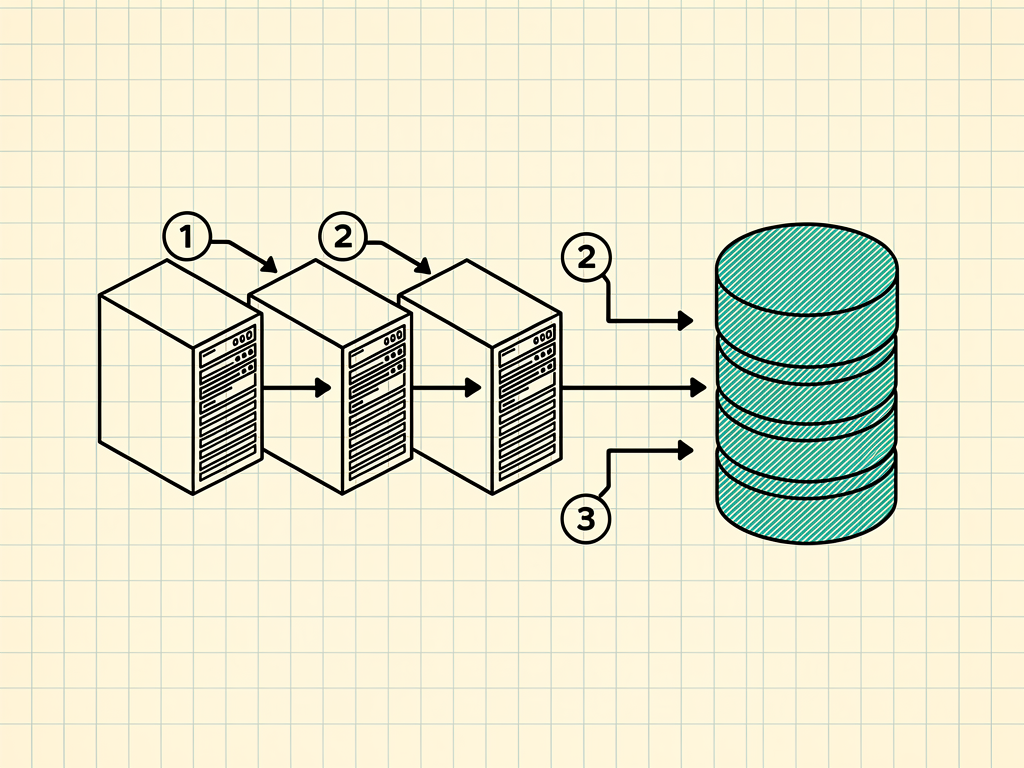
The LLM inference gateway is the request boundary where identity meets policy. It sits between the authenticated caller (a user, an agent, or a service) and any LLM endpoint the caller is authorized to reach. For every request, the gateway resolves four fields, evaluates a policy, and produces an audit record that is independent of the caller and independent of the model. Any component that omits one of the four fields is operating at a different layer.
The inference server generates tokens. The router picks the endpoint. The API gateway (in the traditional sense) enforces authentication and rate limits at the HTTP layer. The LLM inference gateway is the layer that ties identity to authorization to audit for AI-specific traffic.
I want to walk through the four fields the gateway resolves per request, the components it is often confused with, and the audit-write path constraint that determines whether the gateway is producing evidence or producing convenience.
The four fields per request
Every request that reaches the gateway carries an implicit set of unresolved questions. The gateway resolves each one before the request moves upstream.
Field one: verified identity
The caller sends a credential. The gateway resolves the credential to a verified identity: a user ID for a human caller, an agent identity for a service or agent caller, or a workload identity for a batch process. The identity is verified, not asserted. Bearer tokens are validated against the issuer, mTLS certificates are validated against the trust root, and OAuth tokens are validated against the introspection endpoint. Requests with unverifiable credentials fail closed at this step.
Field two: role and authorization context
The verified identity resolves to a role and an authorization context. The role determines what policies apply. The authorization context includes tenant membership, group memberships, and any scope claims from the credential. The gateway attaches this context to the request before the policy evaluation.
Field three: data classification
The prompt is classified against a data sensitivity taxonomy. The taxonomy is deployer-defined but usually includes PII, PHI, PCI, secrets, and internal-restricted classes. The classifier runs inline, before the policy evaluation. Classification results attach to the request as metadata that policy rules can reference.
Field four: policy decision
The policy engine evaluates the request against per-route and per-role rules. Rules can reference any of the resolved fields: identity, role, classification, request path, requested model, and any custom attributes. The decision is one of permit, redact, or deny. Permit decisions carry the authorized-endpoint set the router is allowed to route to. Redact decisions carry the redaction instructions to apply before the request moves upstream. Deny decisions terminate the request and produce an audit record.
What the LLM inference gateway is not
The term "gateway" appears in adjacent components with different responsibilities. Distinguishing them prevents architectural confusion.
Not the inference server
The inference server (vLLM, TGI, Triton, or a hosted API) generates tokens. It receives a prompt and returns a completion. It has no view of the caller identity beyond whatever credential the calling infrastructure attached. It cannot enforce identity-aware policy because the identity context does not travel with the inference request in most deployments.
Not the model router
The router chooses which upstream endpoint handles a permitted request. It operates after the gateway. See the LLM gateway vs LLM router piece for the split.
Not the traditional API gateway
The API gateway (Kong OSS, Envoy, NGINX Plus) enforces HTTP-level authentication, TLS termination, and rate limiting. It does not classify prompt content, does not evaluate LLM-specific policies, and does not produce a per-decision audit record with model and policy context. Some API gateways ship plugins that add LLM-specific policy checks; those plugins effectively add an inference-gateway layer on top of the API gateway.
Not the inference server's request log
Provider APIs (OpenAI, Anthropic, Bedrock, Azure OpenAI) produce request logs. Those logs record the request payload, the response, the token counts, and the timing. They record no verified identity for the natural person or agent behind the request, no policy state, and no classification. The provider log is billing-grade evidence for the API call. It is not audit-grade evidence for the AI decision.
The audit-write path constraint
The audit record produced by the gateway must be committed before the response returns to the caller. This is the write-path independence property that makes the audit record admissible.
Why order matters
If the audit record is written after the response returns, the caller can suppress the write by killing the request between the response and the log commit. The audit becomes a probabilistic record of what happened. A regulator asking for the audit record for a specific request can be told the request produced no record because the process crashed before commit. The evidence disappears at exactly the moment it is most likely to matter.
The commit sequence
Per request, the gateway resolves the four fields, evaluates the policy, forwards the request upstream (or denies it), receives the upstream response (or handles the deny), classifies the response if response-side policy applies, commits the audit record to the append-only store, then returns the response to the caller. The commit happens before the caller sees the response. The application that made the request has no ability to suppress the write.
Where deployments compromise
Deployments that batch audit writes for throughput trade write-path independence for latency. Deployments that write audit records to the same database the application controls trade independence for operational simplicity. Both compromises are visible in the resulting audit record: the batch delay produces gaps under crash, and the shared database produces mutability under application error. The compliance question is which compromises the deployer can accept given the regulatory regime.
What surviving an audit requires
An LLM inference gateway that produces audit-grade evidence commits every per-decision record with the four resolved fields plus the model choice, the upstream endpoint, the timestamps, and a cryptographic signature. The commit precedes the response. The write path is isolated from the caller. The audit store is append-only.
This is the architectural pattern the EU AI Act Article 12, Fannie Mae LL-2026-04, HIPAA audit control 45 CFR 164.312(b), NIST AI RMF MANAGE-4, and DORA ICT audit requirements converge on. Each regime asks the same question at the same request layer.
DeepInspect
This is the architecture DeepInspect was built to provide. DeepInspect is the LLM inference gateway for regulated environments. Every request that reaches it is evaluated against per-route, per-role policies using the identity context the credential carries. The classifier tags the prompt against a sensitivity taxonomy. The policy engine produces the permit, redact, or deny decision.
Every decision produces a per-decision audit record with identity, role, policy version, data classification, decision outcome, and timestamp. The record is signed and tamper-evident. The write path is isolated from the caller and committed before the response returns. When a regulator, an auditor, or an internal reviewer asks for the record of a specific request, the store returns it independent of the application that made the request.
Book a demo today.
Frequently asked questions
- How does an LLM inference gateway differ from a plain reverse proxy?
A plain reverse proxy forwards HTTP requests to an upstream. It does not resolve caller identity beyond the credential the caller attaches, does not classify prompt content, does not evaluate LLM-specific policies, and does not produce audit records with policy and classification metadata. An LLM inference gateway does all four. The reverse proxy is a substrate the gateway can be built on; the gateway is the substrate plus the four resolutions plus the audit commit sequence.
- Does the gateway need to be on-prem or can it be a cloud service?
Both patterns work. On-prem deployment keeps prompt content within the deployer's network boundary, which matters for PHI and other regulated data classes. Cloud deployment reduces operational overhead. The deployment topology does not change the architectural properties: the four fields are resolved, the policy is evaluated, and the audit record is committed regardless of where the gateway process runs.
- What is the latency overhead?
The four resolutions run in parallel with the credential validation, the classification, and the policy evaluation. In production tests, the end-to-end enforcement overhead measures under 50 ms. LLM inference itself takes 500 ms to 5 seconds, so the enforcement overhead is a small percentage of the total request time. Deployments with strict latency budgets can co-locate the gateway with the inference endpoint to reduce network overhead further.
- Can I add response-side policy at the gateway?
Yes. The gateway inspects the upstream response before returning it to the caller. Response-side policy can redact PII from outputs, attach transparency markers for the EU AI Act Article 50 disclosure requirements, or block responses that violate the deployer's content policy. The response-side evaluation produces its own record fields inside the per-decision audit record.
- How does the gateway know what data class applies?
The classifier is deployer-configured. Common approaches use regular expressions for structured data (SSNs, credit cards, HIPAA identifiers), lookup tables for tenant-specific sensitive terms, and lightweight models for unstructured PII. The classifier runs inline before the policy evaluation. Complex classification (large-model-based) sits behind an asynchronous review path that the policy engine can reference through a classification token.
- What if the caller passes a bearer token from a third-party IdP?
The gateway validates the token against the IdP's introspection endpoint or the IdP's JWKS. The verified identity resolves through the IdP's user directory to the deployer's role assignments. This is the standard OIDC pattern; the gateway is the resource server in OAuth terms.